전 세계 약 35억 명이 구강 질환을 앓고 있지만 치과 분야에서 대규모 AI 모델의 임상적 가능성을 종합적으로 비교한 연구는 부족한 상황이다. 이런 공백을 채우는 체계적 리뷰 논문이 arXiv에 게재됐다. PRISMA-ScR 지침에 따라 PubMed·구글 스칼라·Scopus·arXiv 등 4개 데이터베이스를 검색해 독립 검토자 2인이 스크리닝한 결과, 2020년~2026년 발표된 97개 연구가 분석 대상으로 선정됐다.
연구팀은 치과 AI 모델을 아키텍처 패러다임과 치과 특화 정도라는 두 축으로 분류하는 프레임워크를 제안한다. 분석 결과, 언어 생성 모델은 임상 추론·면허 시험·환자 소통 등 텍스트 기반 과제에서 강점을 보이지만 이미지 의존 진단에서는 성능이 고르지 않다. SAM과 CLIP을 치과용으로 변형한 모델은 치아 분할 및 병변 탐지에서 유의미한 성과를 냈다. DentVFM·DentVLM·OralGPT 등 치과 전용 파운데이션 모델은 복잡한 멀티모달 과제에서 가장 높은 성능을 보였으며, 단일 모델보다 통합 파이프라인이 일관되게 우수했다.
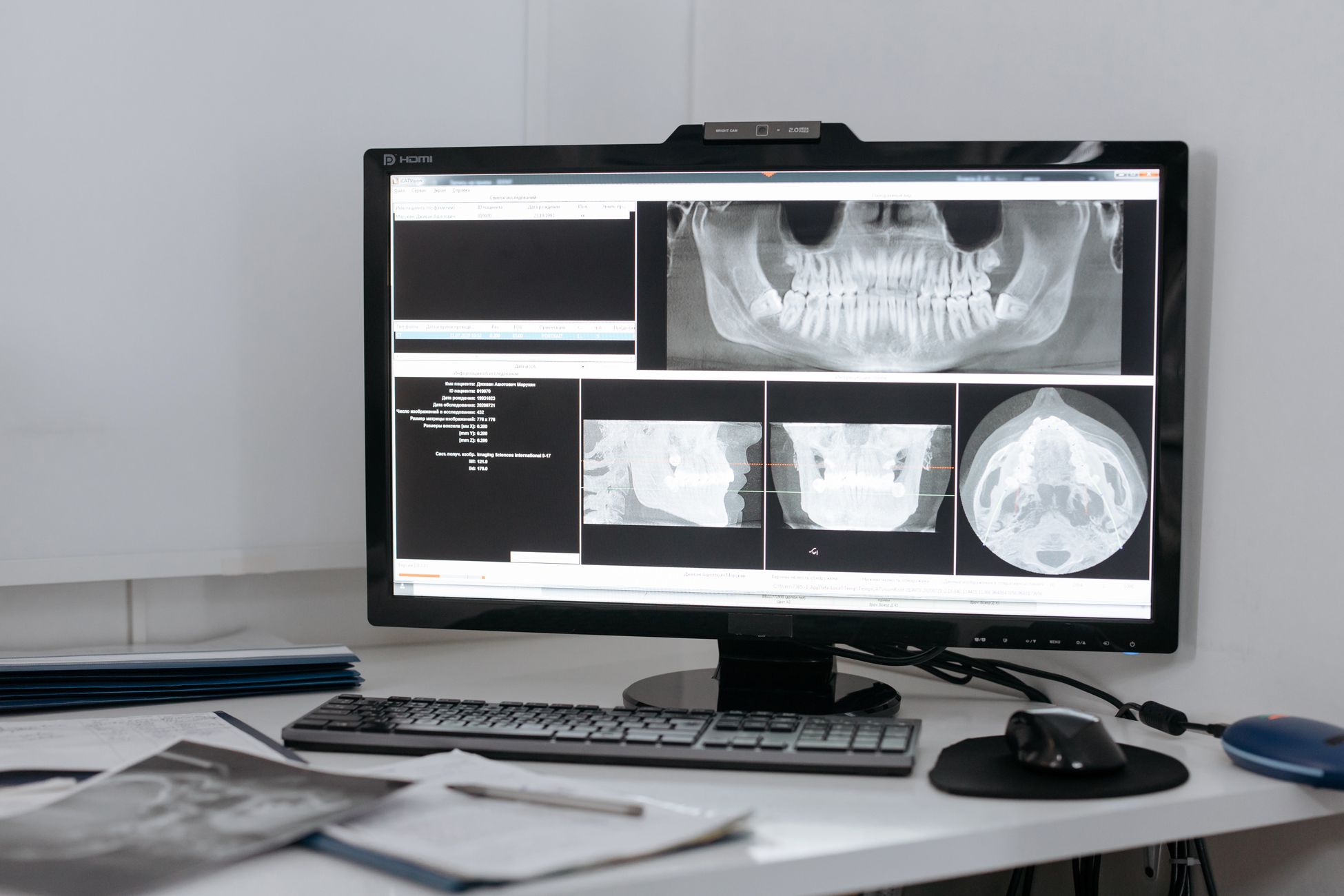
또한 논문은 치과 특화 사전학습이 시각 도메인에 집중돼 있다는 데이터 비대칭 현상을 지적한다. 대규모 치과 텍스트 코퍼스가 부족한 탓에 언어 모델 쪽의 도메인 특화가 제한된다는 설명이다. 연구팀은 범용 모델과 치과 특화 모델이 상호 보완적 역할을 수행하며, 최적 성능은 두 유형을 구조화된 파이프라인에서 결합할 때 나온다고 결론짓는다.
임상 자율 배포를 가로막는 세 가지 지속적 장벽으로는 생성 모델의 환각(hallucination), 주석이 달린 치과 데이터셋의 부족, 표준화된 임상 평가 벤치마크의 부재가 꼽혔다. 이 논문은 치과 AI 연구의 현 주소와 향후 과제를 한눈에 정리하는 기준점이 될 것으로 보인다.
저작권자 © STORIUM 무단전재 및 재배포 금지















{kind=link}