
RoboCup 경기 영상을 바탕으로 자동 중계를 만드는 LLM 기반 체계
RoboCup 경기 영상에서 로봇과 공을 추적해 규칙으로 사건을 뽑고, LLM이 이를 문장으로 바꾸는 arXiv 프리프린트다. 실시간 중계와 경기 후 분석을 ...
RoboCup 경기 영상에서 로봇과 공을 추적해 규칙으로 사건을 뽑고, LLM이 이를 문장으로 바꾸는 arXiv 프리프린트다. 실시간 중계와 경기 후 분석을 ...
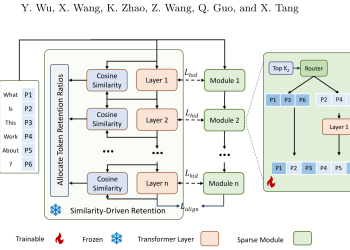
사전학습 LLM을 추가 재학습 없이 층별 희소 모델로 바꾸는 AdaDSF가 GPT-NeoX와 Qwen2.5에서 FLOPs를 줄이며 성능 저하를 억제했는지 확인한 프리프린트다.
ACL 2026 발표 논문은 믿음 표현의 형식·증거성·인식적 태도·어조를 바꿔 LLM의 문맥 수용 차이를 비교했다. 본문과 초록의 유형·모델 수 불일치도 함께 ...
산업 현장의 다중 자율 서브시스템에서 목표 충돌을 실행 전에 포착하는 의도 추상화 계층의 개념 검증을 다룬 arXiv 프리프린트다.

UCLA 연구진이 7일짜리 텍스트 환경에서 8개 모델과 8개 에이전트 구성을 비교했다. 최고 결과도 F1 65.1%에 그쳐 미래 의도 실행의 한계를 ...

대학원생 20명의 파일럿에서 예시형 LLM 스캐폴딩은 즉각적인 문제 품질 향상이 더 컸고, 질문형은 성찰을 돕는다는 인터뷰 반응을 얻었다.

개발자가 오픈 모델을 로컬에서 손쉽게 구동하도록 돕는 올라마가 6500만 달러 시리즈B를 유치했다.

오픈AI가 일부 기관에 선공개했던 GPT-5.6을 솔·테라·루나 세 모델로 나눠 일반에 정식 출시했다.

엔비디아가 네모트론 3 슈퍼를 압축한 퍼즐 75B 모델을 공개했다. 파라미터를 줄여 서버 처리량과 초장문 동시 처리 능력을 크게 끌어올렸다.

AI 최적화 스타트업 리파이언트가 1000만 토큰 컨텍스트 윈도를 갖춘 장문 모델군 프로테아를 대기자 명단 없이 공개했다.

메타의 새 플래그십 모델 뮤즈 스파크 1.1이 멀티에이전트 자동화와 컨텍스트 압축 기능으로 코딩 벤치마크에서 큰 폭으로 도약했다.

xAI가 그록 4.5를 공개했다. 벤치마크 순위는 프런티어 모델에 밀리지만 작업당 비용이 경쟁 모델의 수분의 1 수준이다.









