흉부 X선 판독문 자동 생성에서 강화학습을 활용하기 어려웠던 핵심 이유는 보상 신호 설계의 난점이었다. 판독문은 순서가 정해진 인과적 추론 사슬이 아니라 비순서·독립적인 소견들의 집합으로 구성되기 때문에, 정확 일치 정확도나 단계별 과정 보상 같은 기존 방식이 맞지 않았다. Gulluk 등 연구진(arXiv:2606.00440)은 이 문제를 해결하기 위해 각 판독문을 문장 단위로 분리하고 고정된 문장 트랜스포머로 임베딩해 비순서 임베딩 집합으로 변환하는 방법을 택했다. 생성된 집합과 참조 집합 사이의 집합 간 거리를 연속적이고 치환 불변(permutation-invariant)한 보상으로 사용하는 방식이 SDR(Set-Distance Rewards)의 핵심이다.
두 개 데이터셋과 세 가지 비전-언어 모델(Qwen3-VL-2B/4B, Gemma3-4B)을 대상으로 GRPO 강화학습을 적용한 결과, SDR 기반 후처리 훈련이 지도 파인튜닝과 정확 일치 GRPO 방식을 모두 상회했다. BERTScore, RadGraph F1, CheXbert F1에서 각각 평균 약 6.80%, 7.82%, 4.45%의 상대적 개선이 확인됐다. 또한 동일한 집합 거리 척도를 추론 시 최적 후보 선택(best-of-N selection)에도 적용했는데, 훈련된 모델뿐 아니라 Mistral-Small, Gemini-2.5 Flash-Lite, GPT-4o-mini 등 세 가지 클로즈드소스 LLM에서도 평균 약 16.4%의 BERTScore 개선을 달성했다. 생성 중 저품질 후보를 중도 제거하는 스트리밍 신호로 사용하면 생성 토큰을 50% 이상 절감하면서도 전체 best-of-N 수준의 소견 품질을 유지할 수 있었다.
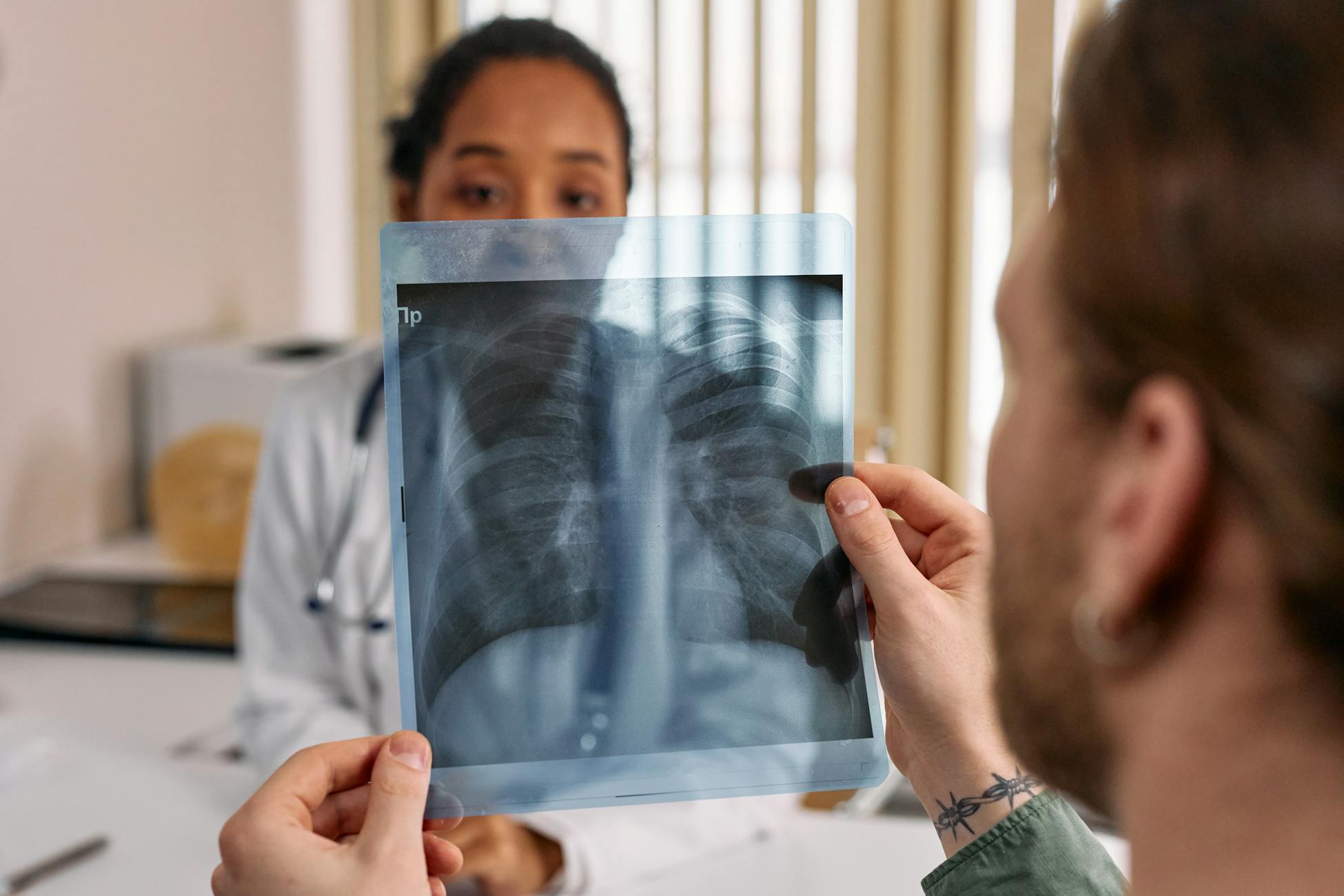
의료 분야 보고서 생성은 단순 텍스트 생성과 달리 소견의 완전성과 임상적 정확성이 동시에 요구된다. 기존 언어 모델 지표가 이 요건을 제대로 반영하지 못한다는 비판이 꾸준히 제기돼 왔는데, SDR은 임베딩 공간에서의 의미적 거리를 통해 소견 집합 수준의 품질을 측정하는 새로운 대안을 제시했다. 연구진은 코드를 공개해 재현 가능성을 확보했으며, 흉부 X선 외 다른 방사선 모달리티나 구조화된 의료 문서 생성으로의 확장 가능성도 열려 있다.
이 연구는 강화학습이 의료 AI에 적용될 때 도메인 특화 보상 설계가 얼마나 중요한지를 잘 보여준다. 정렬되지 않은 소견 집합이라는 의료 문서의 특성에 맞춘 보상 함수 없이는 모델이 임상적으로 유의미한 방향으로 학습하기 어렵다. SDR이 제시한 집합 기반 접근법은 향후 방사선 판독 자동화 시스템의 신뢰성 제고에 기여할 것으로 전망된다.
저작권자 © STORIUM 무단전재 및 재배포 금지













{kind=link}