멀티모달 RL 연구, 출력 형식만 채점한 보상서 해킹률 최대 48.1%
Qwen3-VL 계열의 통제 실험에서 출력 구조만 채점한 보상의 해킹률이 최대 48.1%였다. 이 수치는 특정 Safety VQA 조건의 결과다.
Qwen3-VL 계열의 통제 실험에서 출력 구조만 채점한 보상의 해킹률이 최대 48.1%였다. 이 수치는 특정 Safety VQA 조건의 결과다.
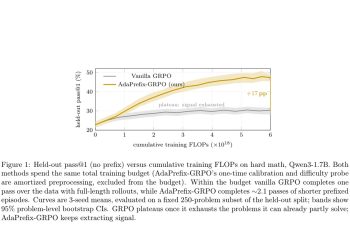
모든 시도가 실패해 학습 신호가 사라지는 어려운 문제를, 정답 앞부분을 힌트로 조절해 학습시키는 기법 AdaPrefix-GRPO가 나왔다. 작은 모델일수록 효과가 컸다.
구글의 JAX 기반 강화학습 라이브러리 튜닉스로 젬마3에 수학 추론 능력을 훈련시키는 전체 파이프라인이 공개됐다.
엔비디아가 기업이 특정 업무에 맞춘 AI 에이전트를 훈련할 때 강화학습을 언제, 어떻게 적용해야 하는지 정리한 실전 가이드를 공개했다.

정적 데이터셋의 고갈 문제를 해결하는 보상 기반 온라인 데이터 합성 기법 RODS가 제안됐다. 400개 시드 데이터로 시작해 1만7천 건 수준의 ...

LLM(대규모 언어 모델) 강화학습에서 새로운 탐색 궤적이 진정한 추론 향상에서 비롯된 것인지, 아니면 암기된 패턴의 변형에서 비롯된 것인지를 구분하는 방법론 ...

연구진이 제로샷 TTS에서 강화학습 기반 LoRA 어댑터로 화자 정체성을 유지하면서 말하기 속도와 피치를 독립적으로 제어하는 GLASS 프레임워크를 제안했다.
GRPO 기반 RLVR의 희소 보상 문제를 해결하는 새 자기증류 기법 CAST가 arXiv에 공개됐다. 정답 없이 자기 교사(self-teacher)로 토큰 수준 어드밴티지를 ...

집합 대 집합 거리를 보상으로 활용하는 SDR 방법이 GRPO 강화학습으로 흉부 X선 판독문 생성에서 BERTScore·RadGraph F1·CheXbert F1을 모두 개선했다.

NeurIPS 2025 MindGames Arena 대회에서 80억 매개변수 오픈소스 모델이 GPT-5를 제치고 1위를 차지한 강화학습 기법이 arXiv에 공개됐다.









