아마존 웹서비스(AWS)가 생성형 AI 추론 엔드포인트의 심층 관측을 위한 ‘SageMaker Insights 대시보드’를 아마존 CloudWatch에 출시했다. 기존 SageMaker 엔드포인트가 호출 횟수, 모델 지연, 오버헤드 지연 등 집계 지표만 제공했다면, 이번 업데이트는 GPU 상태, 토큰 수준 지연, KV(키-값) 캐시 압력, 가용 영역별 트래픽 분산, 추론 컴포넌트 배치, 콜드 스타트 진단 등 100개 이상의 세부 지표를 추가로 제공한다. 이 지표들은 OpenTelemetry 형식으로 CloudWatch에 자동 수집되며, PromQL 호환 엔드포인트를 통해 Grafana나 Datadog 등 기존 관측 도구와도 연결할 수 있다.
SageMaker Insights 대시보드는 세 개 탭으로 구성된다. 성능(Performance) 탭에서는 GPU 상태를 색상 코드 육각형으로 시각화하고, 첫 토큰 수신 시간(TTFT)과 토큰 간 지연(ITL)을 P50/P99 기준으로 추적하며, KV 캐시 이용률과 엔진 요청 압력을 실시간으로 확인할 수 있다. 용량(Capacity) 탭은 GPU·CPU·메모리 이용률 추세를 통해 새 모델 배포 전 여유 용량을 파악하는 데 쓴다. 안정성(Reliability) 탭은 가용 영역별 인스턴스 분산 현황과 콜드 스타트 각 단계별 소요 시간, 용량 부족 오류(ICE) 이력을 보여준다. 새로 생성되는 엔드포인트는 기본값으로 상세 관측 지표가 활성화되며, 기존 엔드포인트는 엔드포인트 구성을 새로 만들어 옵트인하면 된다.
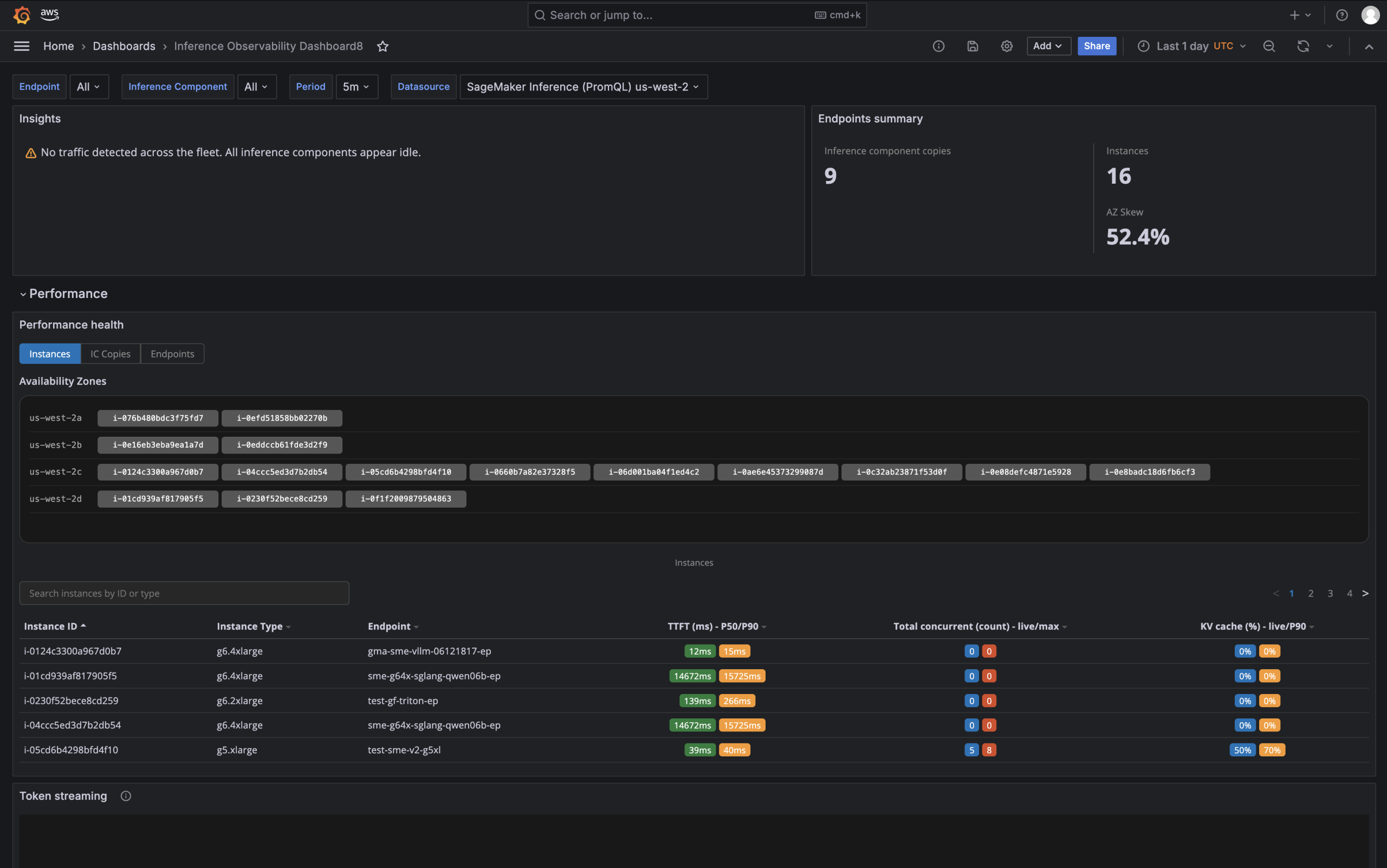
이번 기능이 실질적으로 해결하는 문제는 LLM 서비스 운영의 특수성에서 비롯된다. 추론 단계에서는 지연 시간이 사용자 경험에 직결되고, 수십 개 GPU 인스턴스와 수백 개 모델이 공유 인프라 위에서 돌아가는 환경에서는 문제의 원인을 찾기가 훨씬 어렵다. P99 지연이 급등했을 때 GPU 메모리 부족인지, KV 캐시 포화인지, 가용 영역 불균형인지, 오토스케일링 미발동인지를 수분 내에 진단해야 하는데 기존 집계 지표로는 그 원인을 추적하기 어려웠다. 이번 업데이트는 기계학습 플랫폼 엔지니어와 MLOps 팀, SRE가 이런 진단을 신속하게 할 수 있도록 관측 깊이를 크게 높인 것이다.
비용 측면에서 SageMaker는 상세 관측 지표 발행 자체에는 별도 요금을 부과하지 않는다. 단, CloudWatch OpenTelemetry 수집 표준 요금인 GB당 0.50달러가 적용되며, OTel 지표 보강을 켜면 그에 따른 CloudWatch 지표도 같은 단가로 과금된다. 대규모 GPU 플릿을 운영하는 팀이라면 지표 발행 빈도 설정과 CloudWatch 수집 비용 간 트레이드오프를 사전에 계산해둘 필요가 있다. 경쟁 구도 측면에서 AWS의 이번 발표는 Google Cloud의 Vertex AI 모니터링, Azure의 AI Monitoring, 그리고 Datadog 같은 전문 MLOps 관측 도구들과 정면으로 맞닿는다. AWS의 강점은 SageMaker와 CloudWatch가 기본 통합돼 있어 별도 관측 인프라 구축 없이 즉시 쓸 수 있다는 것이다.
한국 기업 관점에서 이번 기능 출시는 국내 금융·헬스케어·제조 분야에서 LLM 기반 서비스를 AWS 위에서 운영하려는 팀에게 실질적인 도구를 제공한다. 파인튜닝된 한국어 LLM을 배포하는 사례가 늘면서 추론 성능을 안정적으로 관측하고 비용을 통제하는 것이 실무 과제로 부상하고 있다. SageMaker Insights 대시보드가 기본 제공하는 콜드 스타트 해부 기능은 오토스케일링 정책을 조정하는 데 직접 쓸 수 있어, 예측 불가능한 트래픽 스파이크에 대응하는 서비스 운영팀에 실용적 가치가 있다. 이번 출시는 AWS가 LLM 추론 운영의 복잡성을 인프라 공급자가 직접 흡수하겠다는 전략적 방향을 명확히 했다는 점에서 의미가 있다.















{kind=link}