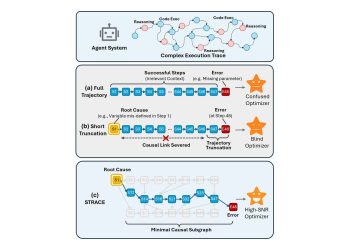
장기 추론 과제를 수행하는 LLM(대규모 언어 모델) 에이전트는 대부분 단일 모델 컨텍스트 안에서 검색 정보와 상호작용 이력을 관리하는 중앙화 메모리 방식을 따른다. 이 구조는 추론 궤적이 길어질수록 컨텍스트 과부하 위험이 높아지고, 이를 피하기 위해 공격적으로 내용을 잘라내면 정보를 돌이킬 수 없이 잃는 딜레마를 낳는다. arXiv에 공개된 새 논문은 이 근본적 트레이드오프를 해소하기 위한 분산 능동 메모리 프레임워크 ActiveMem을 제안했다.
연구진은 인간 인지 시스템에서 영감을 얻어 이 문제를 접근했다. 전전두피질(실행 제어)과 해마(기억 관리)의 기능적 상보성처럼, 핵심 추론 과정에서 에이전트 메모리를 분리하는 이종 프레임워크를 설계했다. 상위 플래너는 증류된 의미 요지(semantic gist)를 활용해 추론을 수행하고, 경량화된 분산 메모리 시스템이 병렬로 작동하며 과제 전반에 걸쳐 요지를 축적하고 통합한다. 기존 중앙화 방식이 컨텍스트를 하나의 모델 안에 모두 몰아넣는 것과 달리, ActiveMem은 메모리 관리 책임을 별도의 경량 시스템으로 위임해 주 추론 경로의 부담을 줄인다.
연구진은 BrowseComp-Plus와 GAIA 벤치마크에서 ActiveMem을 평가했다. 그 결과 오버헤드를 대폭 줄이면서 최고 수준의 정확도를 달성했다고 밝혔다. 장기 에이전트 추론 분야는 웹 탐색이나 복잡한 멀티스텝 태스크 수행처럼 수십~수백 단계의 행동이 필요한 과제에서 기존 LLM의 한계가 두드러지는 영역이다. ActiveMem은 중앙화된 메모리 구조에서 비롯되는 컨텍스트 과부하와 정보 손실 간의 근본적 트레이드오프가 구조 설계로 완화될 수 있음을 실험으로 보여줬다는 점에서 주목받는다.
이번 연구는 LLM 에이전트가 실제 환경에서 장기 과제를 안정적으로 수행하기 위해 메모리 아키텍처 자체를 재설계해야 한다는 방향을 제시한다. 인간 인지 구조를 직접 모사한 분산 설계 원리가 에이전트 AI의 실용성을 높이는 데 실질적인 단서가 될 수 있는지에 대한 후속 연구가 기대된다.
저작권자 © STORIUM 무단전재 및 재배포 금지















{kind=link}