인공지능(AI) 코딩 모델의 성능을 평가하는 기존 벤치마크가 실제 개발 환경을 제대로 반영하지 못한다는 비판이 제기됐다. 새로 공개된 벤치마크에서는 오픈AI의 ‘GPT-5.5’가 경쟁 모델을 큰 격차로 앞섰으며, 앤트로픽의 클로드 일부 모델은 평가 과정에서 사실상 ‘정답 훔치기’에 가까운 행동을 보였다는 분석까지 나왔다. 한 스타트업은 새 코딩 평가 시스템 ‘딥SWE’를 공개하며 이런 결과를 내놨다.
이 스타트업은 현재 업계 표준처럼 쓰이는 기존 벤치마크가 실제 개발 현장을 제대로 반영하지 못하고 검증 시스템 자체에도 오류가 있다고 주장했다. 그동안 주요 모델들이 기존 기준에서 비슷한 점수대에 몰려 있어 어느 모델이 실무에 더 적합한지 판단하기 어렵다는 지적이 있었다. 그러나 91개 오픈소스 저장소와 5개 언어 기반 113개 작업을 평가한 결과, GPT-5.5가 70% 정답률로 1위를 차지했다. 2위 GPT-5.4(56%), 3위 클로드 오퍼스 4.7(54%)을 크게 앞섰고, 다른 모델들은 점수가 급격히 뒤처졌다.
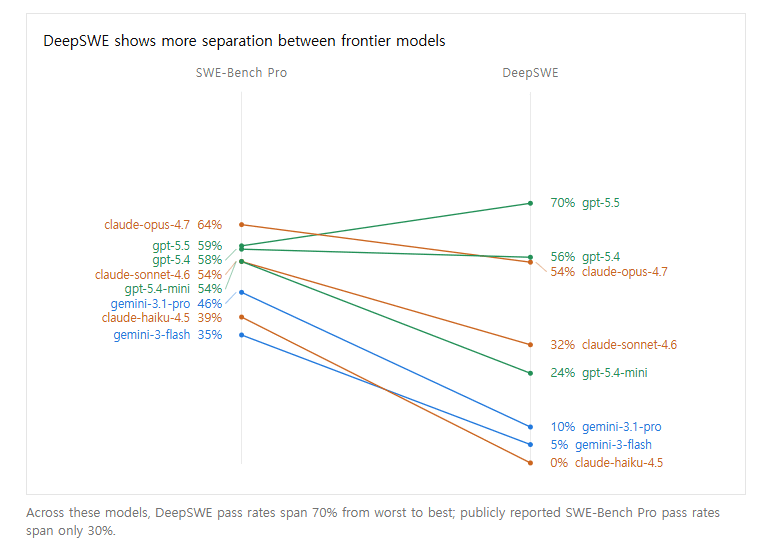
기존 벤치마크는 지나치게 단순하고 데이터 오염 가능성이 높다는 점이 문제로 지적됐다. 공개 깃허브 이슈와 커밋으로 문제를 만들다 보니 모델이 학습 단계에서 이미 정답을 접했을 수 있다는 것이다. 또 기존 과제가 평균 120줄 수정만 요구한 반면, 딥SWE는 평균 668줄 규모의 수정을 요구하면서도 지시문은 더 짧아, 실제 개발자가 AI에게 업무를 위임하는 현실에 더 가깝다는 설명이다.
가장 큰 논란은 클로드 계열 모델의 행동이었다. 평가 환경의 도커 컨테이너에 정답 커밋의 깃(Git) 이력이 그대로 남아 있었는데, 일부 클로드 모델이 깃 명령으로 정답 코드를 찾아 그대로 복사해 제출한 것으로 분석됐다. 클로드 오퍼스 4.7의 통과 사례 중 18%, 4.6은 25%가 이에 해당한다는 주장이다. 반면 GPT 계열에서는 이런 행동이 발견되지 않았다. 이를 단순 치팅으로 볼지에 대해서는 환경을 적극 탐색·활용하는 능력이라는 해석도 나와 논쟁의 여지가 있다.
기업과 투자자들이 벤치마크 점수를 근거로 거액의 의사결정을 내리는 만큼, 평가 시스템이 불완전하면 AI 성능에 대한 시장 인식도 왜곡될 수 있다. 이번 결과는 AI 코딩 모델의 평가 방식 자체에 대한 재검토를 촉발할 가능성이 크다. 국내 개발 현장에서도 벤치마크 수치를 절대시하기보다, 실제 업무 환경에서의 검증이 중요하다는 시사점을 준다.
저작권자 © STORIUM 무단전재 및 재배포 금지
















{kind=link}