다양한 문화, 가치관, 선호를 가진 사람들을 대표하는 페르소나(persona) 집합을 활용해 생성 AI의 다원적 정렬(pluralistic alignment) 수준을 평가하는 프레임워크가 arXiv에 공개됐다. AI 정렬 연구는 AI 시스템이 인간의 가치와 의도에 맞게 동작하도록 만드는 것을 목표로 한다. 그러나 기존 정렬 연구는 단일한 또는 단수의 인간 선호를 기준으로 삼는 경우가 많아, 다양한 배경과 가치관을 가진 실제 사용자들이 AI를 경험하는 방식의 다양성을 충분히 반영하지 못한다는 비판이 있었다. 이 연구는 이 다양성을 체계적으로 측정하는 평가 체계를 제안한다.
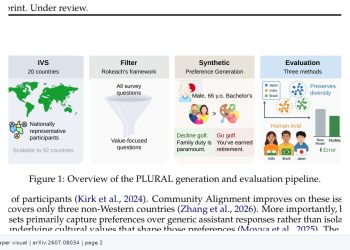
연구팀은 단일한 평가 함수 대신 다양한 인간 관점을 대표하는 합성 인지 프로필(synthetic cognitive profiles)의 구조화된 집합을 평가 기준으로 삼는 프레임워크를 제안했다. 핵심 발견은 두 가지다. 첫째, 최신 생성 AI 구조가 이러한 평가용 페르소나를 높은 일관성으로 구현하고 유지할 수 있어, 실제 세계의 합의 다양성을 더 가깝게 반영하는 관점 의존적 벤치마킹이 가능하다는 점이다. 둘째, 그러나 순차적 추론과 무작위적 프롬프트 변동을 거치면 페르소나의 일관성이 체계적으로 저하되는 현상, 즉 ‘상태 공간 표류(state-space drift)’와 의미적 불일치가 나타난다는 점이다. 연구팀은 이로부터 정적인 정렬 제약만으로는 시간에 걸쳐 견고한 평가 행동을 유지하기 어렵다고 진단한다.
이 연구는 AI 공정성과 포용성 논의에서 중요한 시사점을 제공한다. 단일 문화권이나 단일 가치 체계를 중심으로 훈련된 AI가 전 세계 다양한 사용자들에게 배포될 때 발생하는 불평등 문제를 정량적으로 측정할 수 있는 도구가 필요하다는 공감대가 커지고 있다. 한국을 비롯한 비서구권 사용자들의 문화적 맥락이 글로벌 AI 모델에서 어떻게 반영되는지 평가하는 데도 이 프레임워크를 활용할 수 있다. 다만 페르소나 설계 자체에 연구자의 편향이 반영될 수 있다는 한계와, 실제 사람의 응답과 시뮬레이션 결과 사이의 간극 문제는 지속적으로 보완이 필요하다.
국내 AI 기업과 정책 연구자들은 이 프레임워크를 참고해 한국 사용자의 다양한 가치와 문화적 맥락이 AI 시스템에 적절히 반영되는지 평가하는 자체 도구를 개발할 수 있다. AI 서비스 다양성과 포용성 기준을 마련하는 규제 논의에서도 페르소나 기반 평가 방법론은 실증적 근거로 활용될 수 있다. 특히 교육, 의료, 법률 등 사회적 영향이 큰 AI 서비스에서 다원적 정렬 수준을 정기적으로 점검하는 거버넌스 체계 수립에 이 연구가 기여할 것으로 기대된다.
저작권자 © STORIUM 무단전재 및 재배포 금지















{kind=link}