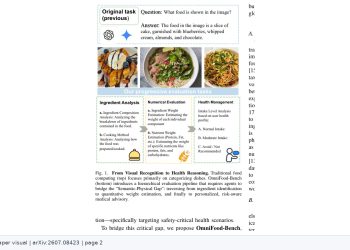
비전-언어 모델(VLM, Vision-Language Model)이 일반적인 멀티모달 이해에서는 강점을 보이면서도 시각적 공간 계획 작업에서는 여전히 취약하다는 점에 주목한 연구가 발표됐다. 연구팀은 이 한계가 ‘지각-추론 모달리티 격차(perception-reasoning modality gap)’에서 비롯된다고 분석했다. 기호 기반 계획은 명시적 객체와 제약 조건을 직접 활용하는 반면, 시각 기반 계획은 픽셀에서 잠재적 상태 구조를 먼저 복원한 뒤 그것을 토대로 유효한 행동을 추론해야 한다는 이중 병목이 존재한다는 설명이다.
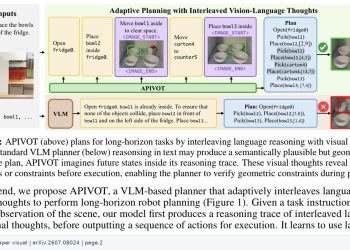
이 문제를 해결하기 위해 연구팀은 MGSD(Modality-Gap-Aware Self-Distillation)라는 2단계 자기증류 프레임워크를 제안했다. 첫 번째 단계는 콜드스타트 그라운딩으로, 시각 학생 모델이 초기부터 신뢰할 수 있는 상태 표현을 갖추도록 해 지각 노이즈를 최소화한다. 두 번째 단계에서는 기호 상태를 입력으로 받는 교사 모델이 학생 모델의 시각 롤아웃 접두어를 감독하는 방식으로 계획 능력을 전이한다. 기호 데이터는 훈련에만 활용되며, 추론 단계에서는 순수하게 시각 입력만 사용된다.
시각 계획 벤치마크 실험 결과, MGSD는 4B와 8B 두 규모의 백본 모델 모두에서 성능을 일관되게 높였다. 매크로 평균 기준으로 4B 모델은 19.3%, 8B 모델은 18.4% 향상됐다. 연구팀은 이 성능 개선이 시각적 상태 복원 능력과 최적 경로 추론 능력 양쪽 모두에서 비롯된 것임을 추가 실험으로 확인했다. MGSD의 코드는 깃허브(GitHub)를 통해 공개됐다.
시각 공간 계획은 로봇 내비게이션, 자율주행, 가정용 서비스 로봇처럼 AI가 물리 공간을 이해하고 행동을 설계해야 하는 응용 분야의 핵심 능력으로 꼽힌다. 비전-언어 모델이 이미지 설명이나 질의응답에서는 뛰어난 성능을 보이면서도 ‘어떻게 움직여야 목표에 도달하는가’를 따지는 계획 작업에서 약점을 보여 온 것은 이 분야의 오랜 난제였다. 이번 연구가 기호 데이터를 추론이 아닌 학습 단계에만 활용해 실제 작동 시에는 시각 입력만으로 계획을 세우도록 한 점은, 추가 센서나 외부 정보 없이도 모델 자체의 공간 추론 능력을 끌어올릴 수 있다는 가능성을 보여준다. 코드 공개로 후속 연구와 산업 적용 검증도 한층 수월해질 전망이다.
저작권자 © STORIUM 무단전재 및 재배포 금지













{kind=link}