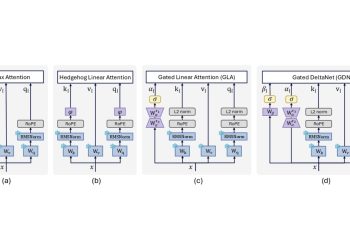
확산 대규모 언어모델(dLLM)은 병렬 디코딩을 통해 자기회귀 모델의 대안으로 주목받고 있지만, 기존 사후 훈련 방식은 대부분 토큰 간 내재적 의존성을 무시한 랜덤 마스킹 전략에 의존한다는 한계가 있다. 연구팀은 dLLM의 어텐션 패턴을 실증적으로 분석해, 마스킹되지 않은 문맥에 강하게 집중하는 토큰일수록 생성 안정성이 높고 추론에서 더 중요한 역할을 한다는 사실을 밝혔다.
이 발견에 기반해 연구팀은 어텐션 구조에 따라 훈련과 최적화를 정렬하는 프레임워크 AGDO(어텐션 기반 디노이징 및 최적화)를 제안했다. AGDO는 어텐션 구조를 기반으로 디노이징 순서를 결정하고, 지도 파인튜닝과 강화학습 과정에서 어텐션에 중요한 토큰을 강조한다. 이는 단순히 마스킹을 무작위로 적용하던 기존 방식에서 벗어나 토큰의 중요도를 훈련 신호에 직접 반영한 접근이다.
수학 및 코딩 벤치마크 실험에서 AGDO는 dLLM의 최신 사후 훈련 방법들을 일관되게 능가하며 추론 성능 향상을 입증했다. 수학과 코딩은 토큰 간 논리적 의존성이 강해 생성 순서가 결과에 큰 영향을 미치는 영역으로, 어텐션이 알려주는 의존 구조를 디노이징 순서에 반영한 전략이 이런 과제에서 특히 유리하게 작용한 것으로 풀이된다.
자기회귀 모델이 토큰을 한 개씩 순차 생성하는 것과 달리 확산 언어모델은 여러 토큰을 동시에 복원할 수 있어 추론 속도 측면에서 잠재력이 크지만, 무엇을 먼저 확정할지 정하는 문제가 성능의 관건으로 남아 있었다. 연구팀은 어텐션 구조를 활용한 이 방법이 확산 언어모델의 사후 훈련 효율을 높이는 유망한 방향을 제시한다고 밝혔다.
저작권자 © STORIUM 무단전재 및 재배포 금지















{kind=link}