대규모 언어 모델(LLM)에서 유해하거나 불필요한 지식을 선택적으로 제거하는 기술, 이른바 ‘언러닝(unlearning)’ 연구에서 새로운 접근법이 제시됐다. 연구팀은 영공간 제약 응답 지정 언러닝(NSRU)이라는 투영 제약 저랭크 프레임워크를 소개하며, 삭제 대상 지식을 억제하는 동시에 모델의 유익한 능력을 유지하는 방법을 제안했다.
NSRU는 각 삭제 쿼리에 대해 원하는 대체 동작을 명시하는 안전 목표 응답을 명시적으로 구성하고, 원치 않는 콘텐츠를 억제하는 구조로 설계됐다. 적응 범위를 국소화하기 위해 정상 숨겨진 표현에서 모듈별 유지 부분공간을 추정한 뒤, 직교 투영된 저랭크 매개변수화를 통해 LoRA(저랭크 적응) 업데이트를 유지 부분공간의 영공간으로 한정한다. 이 제약된 매개변수화 아래 안전 목표 학습, 원치 않는 응답 억제, 유지 보존을 동시에 최적화하는 목적 함수가 적용된다.
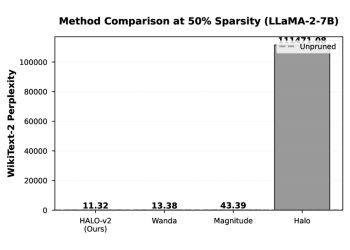
연구팀은 TOFU 벤치마크 실험에서 NSRU가 삭제 집합의 추출 가능한 지식을 효과적으로 억제하는 동시에 유지 QA(질의응답) 성능과 모델 유틸리티, 안전 목표 정렬을 기존 대표 기준선 대비 개선함을 확인했다. 또한 WMDP 벤치마크에서는 위험 도메인 정확도를 무작위 선택 수준 근방으로 낮추면서도 광범위한 MMLU 유틸리티를 유지하는 결과를 보였다. 절제 실험은 안전 목표 감독, 원치 않는 응답 억제, 유지 손실, 영공간 투영 업데이트 각각이 상호 보완적 역할을 함을 뒷받침한다.
LLM 언러닝은 AI 안전성과 저작권·개인정보 보호 관점에서 주목받는 연구 분야다. 기존 언러닝 기법들은 삭제 대상 답변을 억제하는 데 집중했으나, 업데이트 지역성이 충분히 제어되지 않아 모델의 유익한 능력까지 손상시키는 부작용이 보고돼 왔다. NSRU는 영공간 투영이라는 기하학적 제약을 도입해 이 문제를 해결하려 한 시도로, LLM 안전성 확보를 위한 정밀 제어 언러닝 기술 발전에 기여할 것으로 기대된다.
저작권자 © STORIUM 무단전재 및 재배포 금지













{kind=link}