사전훈련 데이터 규모가 늘어날수록 다운스트림 샘플 복잡도가 감소하는 경험적 현상을 이론적으로 증명한 연구가 arXiv에 발표됐다. 연구팀은 복잡도 최소화(complexity minimization)라는 새로운 메타 표현 학습 프레임워크를 도입하고, 사전훈련부터 다운스트림 회귀까지를 아우르는 엔드투엔드 이론 분석을 통해 메타 훈련 데이터 양이 증가할수록 퓨샷(few-shot) 적응의 오차율이 개선됨을 증명했다. 또한 기존 메타 학습 방법에 복잡도 정규화를 도입하면 다운스트림 샘플 효율이 일관되게 향상된다는 실험 결과도 함께 제시됐다.
사전훈련은 현대 머신러닝의 기본 패러다임이 됐으며, 핵심 실증적 이점 가운데 하나는 사전훈련 데이터 규모가 커질수록 다운스트림 작업에서 더 적은 데이터로 좋은 성능을 낼 수 있다는 점이다. 그러나 기존 이론 프레임워크는 이 현상을 완전히 설명하지 못했다. 특히 사전훈련과 다운스트림 학습을 연결하는 통합적 이론 분석이 부재했으며, 데이터 스케일이 왜 다운스트림 샘플 복잡도를 줄이는지에 대한 엄밀한 근거가 필요한 상황이었다.

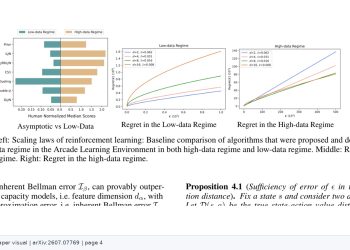
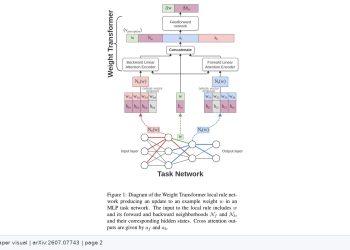
복잡도 최소화 프레임워크는 각 도메인에 최적화된 다운스트림 모델 복잡도를 평가하고, 소스 도메인 전반에서 최악 경우 복잡도를 최소화하는 방식으로 표현을 학습한다. 이 설계는 분포 외 일반화를 고려한 표현을 유도하면서도 이론 분석이 가능한 구조를 제공한다. 이론 결과는 복잡도 최소화가 이 스케일링 거동을 증명 가능한 방식으로 포착함을 보여주며, 오차율이 메타 훈련 데이터 양에 따라 개선되는 수학적 의존성을 명확히 한다.
데이터 스케일링 법칙은 대형 언어 모델 개발에서 중요한 설계 지침으로 자리 잡았다. 이번 연구는 스케일링 법칙을 메타 학습의 틀에서 이론적으로 정초한다는 점에서 의미가 있다. 사전훈련이 왜 더 나은 퓨샷 학습자를 만드는지에 대한 이론적 이해를 높이는 이 연구는, 데이터 효율적인 AI 시스템 설계와 소규모 데이터 환경에서의 적응 학습 연구에 이론적 근거를 제공한다.
저작권자 © STORIUM 무단전재 및 재배포 금지














{kind=link}