트랜스포머 모델 최적화에서 가중치 공간 기하학(weight-space geometry)이 중요한 역할을 하지만, 지금까지는 모든 가중치 행렬에 동일한 다양체(manifold) 제약을 일괄 적용하는 방식이 일반적이었다. 새로운 연구는 트랜스포머의 각 모듈이 서로 다른 기하학적 구조를 선호한다는 가설을 검증하고, 이를 모듈별로 구분해 적용하면 성능이 개선된다는 결과를 제시했다.
연구팀은 GPT-2 사전학습(pretraining) 환경에서 Manifold Muon 최적화 기법을 적용해, 어텐션(attention) 블록과 MLP 블록에 Stiefel 제약과 DGram 제약을 레이어별로 다르게 할당하는 실험을 수행했다. 그 결과, 어텐션 레이어에 Stiefel 기하학을 적용하고 MLP 레이어에 DGram 기하학을 적용하는 구성이 테스트된 설정 가운데 가장 높은 성능을 기록했다. 반면 이 두 가지를 반대로 배치하거나 모든 레이어에 DGram을 적용하면 동일한 하이퍼파라미터 세팅 아래서 학습이 불안정해지는 것으로 나타났다.
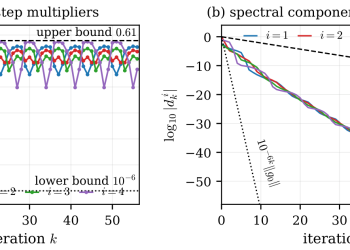
이 불안정성의 원인으로 연구팀은 DGram 제약이 적용된 어텐션 가중치에서 특이값(singular value)이 증가하는 현상을 지목했다. 특이값 증가는 어텐션 로짓을 과도하게 키워 소프트맥스 포화(softmax saturation)를 유발하며, 이것이 학습 발산의 주된 요인이라는 분석이다. 이 발견은 트랜스포머 최적화에서 대칭성 인식과 기하학 인식 접근법을 적용할 때 모듈 유형에 따라 제약을 차별화해야 한다는 점을 시사한다.
이 연구는 신경망 최적화의 기하학적 기초를 모듈 단위에서 재검토하는 방향을 제시한다. 하나의 기하학 규칙을 전체 모델에 일률 적용하는 관행 대신, 레이어 역할에 맞는 맞춤형 다양체 제약이 더 안정적이고 효율적인 학습으로 이어질 수 있다는 근거를 제공했다는 점에서 의의가 있다.
저작권자 © STORIUM 무단전재 및 재배포 금지















{kind=link}