강화학습 분야에서 널리 쓰이는 PPO(근접 정책 최적화, Proximal Policy Optimization) 알고리즘이 비정상(non-stationary) 환경과 연속 학습(continual learning) 상황에서 구조적 한계를 드러낸다는 분석과 함께, 이를 극복하기 위한 GTR(가우시안 신뢰 구역 정책 최적화, Gaussian Trust Region Policy Optimization) 알고리즘이 제안됐다. 연구팀은 PPO의 실패 원인이 모델 용량 부족이나 클리핑 제약 과도함에 있지 않으며, 기하학적 인식 없이 방향성 비효율적인 지역 업데이트를 반복해 의미 있는 행동 전환이 누적되지 못하는 데 있다고 밝혔다.
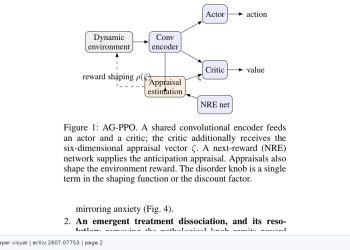
GTR은 가우시안 커널을 이용해 신뢰 구역을 재형성하는 방식으로 이 문제를 해결한다. 이 신뢰 구역은 제한적이면서도 비단조적(non-monotonic)인 특성을 가져 지역 안정성을 유지하는 동시에, 높은 어드밴티지(advantage) 업데이트가 지속될 때 점진적으로 이완된다. 추가로 최근 정책 궤적에 적응하는 혼합 가우시안 앵커(Mixture Gaussian Anchor) 메커니즘을 도입해 분산을 줄이고 행동 전환을 더 효과적으로 유도한다.

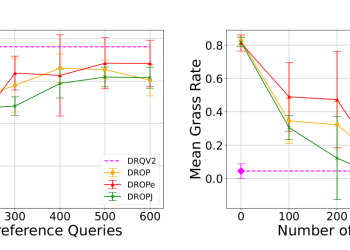
GTR은 아키텍처에 독립적으로 설계돼 게임 환경, 로봇 시뮬레이션, 오픈 월드 탐색 과제, LLM(대규모 언어 모델, Large Language Model) 파인튜닝(fine-tuning) 등 다양한 영역에 적용됐으며 모두에서 성능 향상을 보였다. 특히 보상 신호나 환경 동학(dynamics)이 지속적으로 변화하는 비정상 시나리오에서 기존 PPO 대비 뚜렷한 개선이 확인됐다.
PPO는 단순성과 안정성 덕에 기업 강화학습 시스템과 LLM 인간 피드백 기반 학습(RLHF)에서 표준 알고리즘으로 광범위하게 활용된다. 이번 연구는 PPO의 기하학적 한계를 이론적으로 규명하고 신뢰 구역 설계 개선만으로 비정상 환경 적응력을 크게 높일 수 있음을 보여주었다는 점에서, 강화학습 기반 AI 시스템의 실세계 배포 안정성 향상에 기여할 것으로 전망된다.
저작권자 © STORIUM 무단전재 및 재배포 금지














{kind=link}