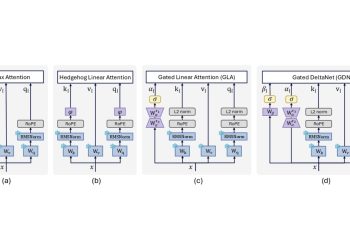
대규모 언어 모델(LLM)의 장문맥 처리 능력을 높이기 위해 선형 어텐션 메커니즘이 주목받고 있지만, 기존 다중 상태 선형 어텐션 방식은 고정된 상태 병합 정책을 사용해 토큰 중요도 변화에 적응하지 못한다는 한계가 있었다. 연구팀은 이 문제를 해결하기 위해 동적 메모리 모델링 프레임워크 DLA(Dynamic Linear Attention)를 제안했다.
DLA는 두 가지 핵심 구성 요소로 이루어진다. 첫째, 정보 인식 동적 상태 병합(Information-Aware Dynamic State Merging)은 토큰 수준의 정보 변화량을 기준으로 상태 경계를 적응적으로 결정한다. 의미 전환이 일어나는 구간 주변에는 고해상도 표현을 유지하고, 변화가 적은 안정 구간은 공격적으로 압축한다. 둘째, 용량 경계 메모리 모델링(Capacity-Bounded Memory Modeling)은 인접한 저정보 상태를 선택적으로 병합하면서 고정 크기의 상태 캐시를 시간 순서대로 유지해 정보 손실을 최소화하며 메모리 증가를 제어한다.

연구팀은 DLA를 두 가지 서로 다른 선형 어텐션 모델에 사전 학습 단계부터 적용하고, 세 가지 범주에 걸친 16개 데이터셋에서 평가를 수행했다. 실험 결과 DLA는 기존 최고 수준의 방식들을 일관되게 능가하는 성능을 보였다. 표준 어텐션의 이차 복잡도 문제를 피하면서도 중요한 토큰 정보를 잃지 않는 균형점을 찾은 것이 성공 요인으로 분석된다.
LLM의 컨텍스트 창을 수십만 토큰 이상으로 확장하려는 시도가 이어지는 상황에서, 처리 효율과 표현 품질을 동시에 확보하는 선형 어텐션 연구의 중요성은 갈수록 높아지고 있다. DLA는 고정 정책의 한계를 극복한 동적 접근법으로서 향후 장문맥 언어 모델 설계에 영향을 줄 것으로 전망된다.
저작권자 © STORIUM 무단전재 및 재배포 금지















{kind=link}