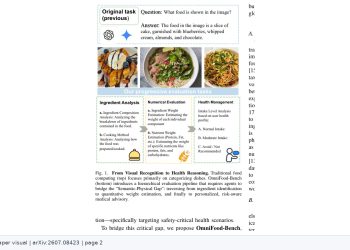
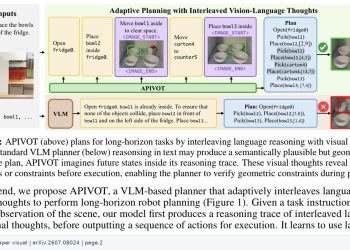
VLESA(Vision-Language Embodied Safety Agent)는 사람의 활동을 1인칭(에고센트릭) 영상으로 모니터링하고, 위험한 행동이 예측될 때 실시간으로 안전 개입을 수행하는 AI 프레임워크다. 연구의 핵심 문제 의식은 동일한 행동도 맥락에 따라 안전하거나 위험할 수 있다는 점이다. 기존 시스템이 행동 자체만 보고 판단하는 데 반해, VLESA는 사용자의 목표와 의도를 함께 추론하는 ‘목표 인식 평가(goal-aware evaluation)’ 방식을 채택한다.
프레임워크는 크게 두 구성 요소로 이뤄진다. 첫 번째는 의도-행동 예측 에이전트로, 영상 입력에서 사용자의 목표를 추론하고 앞으로 발생할 행동을 예측한다. 두 번째는 GRPO(Group Relative Policy Optimization) 방식으로 학습한 Q-필터로, 별도 재학습 없이 추론된 의도를 기준으로 행동의 안전성을 판단하는 제약적 디코딩을 수행한다. 연구팀은 1인칭 영상 프레임과 목표 조건부 안전 레이블을 결합한 데이터셋도 함께 구축했다.

ASIMOV-2.0 벤치마크를 이용한 평가에서 VLESA는 기준 모델 대비 정확한 시점에서의 개입 정확도가 높았고, GRPO로 학습한 Q-필터가 목표 조건부 제약 디코딩을 통해 행동 안전성을 41퍼센트포인트 이상 개선했다고 논문은 밝힌다. 연구팀은 1인칭 영상 프레임과 목표 조건부 안전 레이블을 짝지은 데이터셋을 함께 도입해 이 방식을 뒷받침했다.
VLESA가 다루는 문제는 산업 현장, 의료 시설, 가정 내 돌봄 등 AI 에이전트가 사람의 활동을 보조하는 다양한 환경에서 안전성을 어떻게 보장할 것인가라는 실질적 과제와 맞닿아 있다. 행동 인식에서 행동 예측과 의도 추론을 통합하는 방향성은 구현 AI(Embodied AI) 안전 연구의 진전을 보여주는 사례로 주목된다.
저작권자 © STORIUM 무단전재 및 재배포 금지














{kind=link}